PDF2Audio
综合介绍
PDF2Audio 是一个开源应用程序,它使用人工智能将PDF文档转换为音频文件。该工具首先会分析PDF文件的内容,包括文本、图表和图片等元素,然后利用大型语言模型(LLM)来理解这些内容的结构和逻辑关系,并生成一份适合朗读的文稿。接着,程序会调用文本转语音(TTS)服务,将这份文稿转换成听起来很自然的语音。用户可以根据自己的需求,将PDF转换成不同形式的音频,比如播客、讲座录音或者内容摘要。此外,用户还可以对生成的文稿进行修改,或者向模型提供具体的改进建议,以多次迭代优化最终的音频效果。
功能列表
- PDF转音频:将一个或多个PDF格式的文档转换成音频文件。
- 智能文稿生成:利用大型语言模型(如OpenAI的GPT模型)分析和理解PDF内容,并生成流畅、自然的讲述文稿。
- 多样化输出模板:提供多种预设模板,可将内容转换成播客、讲座、摘要等不同风格的音频。
- 自定义模型与声音:用户可以选择不同的文本生成模型和语音模型,并为不同的讲述者选择不同的声音。
- 迭代式内容编辑:支持用户对生成的文稿草稿进行编辑,并可以向模型提供具体的修改指令或宽泛的改进方向,从而对音频内容进行调整和优化。
- 在线与本地部署:提供了多种使用方式,包括在Google Colab云端环境中运行,或在本地计算机上进行安装部署。同时,项目也在Hugging Face Spaces上提供了在线体验版本。
- Web用户界面:通过Gradio库创建了一个简单易用的网页界面,用户只需在浏览器中打开指定网址,即可上传文件并完成所有操作。
使用帮助
PDF2Audio提供了一个可视化的操作界面,让用户可以轻松地将PDF文档转换成音频。它的安装过程需要一些基础的命令行知识,但操作起来非常直接。
安装流程
要在你自己的电脑上使用PDF2Audio,需要先完成环境的配置。以下是详细的安装步骤,主要使用Conda进行环境管理。
- 克隆代码仓库首先,打开终端(在Windows上是命令提示符或PowerShell,在macOS或Linux上是Terminal),然后输入以下命令,将项目的代码从GitHub下载到你的电脑上。
git clone https://github.com/lamm-mit/PDF2Audio.git下载完成后,进入项目目录。
cd PDF2Audio - 安装Conda(如果尚未安装)Conda是一个开源的软件包管理系统和环境管理系统。如果你的电脑上没有安装,需要先从Miniconda的官方网站下载并安装。根据你的操作系统(Windows, macOS, Linux)选择对应的版本进行安装。
- 创建并激活Conda环境为了不和你电脑上其他Python项目产生冲突,我们为PDF2Audio创建一个独立的环境。
conda create -n pdf2audio python=3.9这个命令会创建一个名为
pdf2audio的环境,并指定使用Python 3.9版本。创建成功后,激活这个环境。conda activate pdf2audio成功激活后,你的终端提示符前面会出现
(pdf2audio)的字样。 - 安装依赖库在激活的环境中,使用
pip工具安装所有必需的Python库。项目已将所有依赖项列在了requirements.txt文件中。pip install -r requirements.txt - 设置OpenAI API密钥PDF2Audio依赖OpenAI提供的GPT和TTS服务,因此你需要一个有效的API密钥。
- 在项目的根目录(
PDF2Audio文件夹内)创建一个名为.env的文件。 - 打开这个文件,并添加以下内容,将
your_api_key_here替换成你自己的密钥。
OPENAI_API_KEY=your_api_key_here - 在项目的根目录(
操作流程
完成安装和配置后,就可以启动程序并开始使用了。
- 启动应用程序确保你仍然在项目的根目录,并且
pdf2audio的Conda环境已经激活。运行以下命令来启动Web应用:python app.py - 访问操作界面启动成功后,终端会显示一个本地网址,通常是
http://127.0.0.1:7860。复制这个网址,在你的浏览器(如Chrome, Edge或Safari)中打开它。你将看到一个由Gradio生成的简洁页面。 - 使用功能
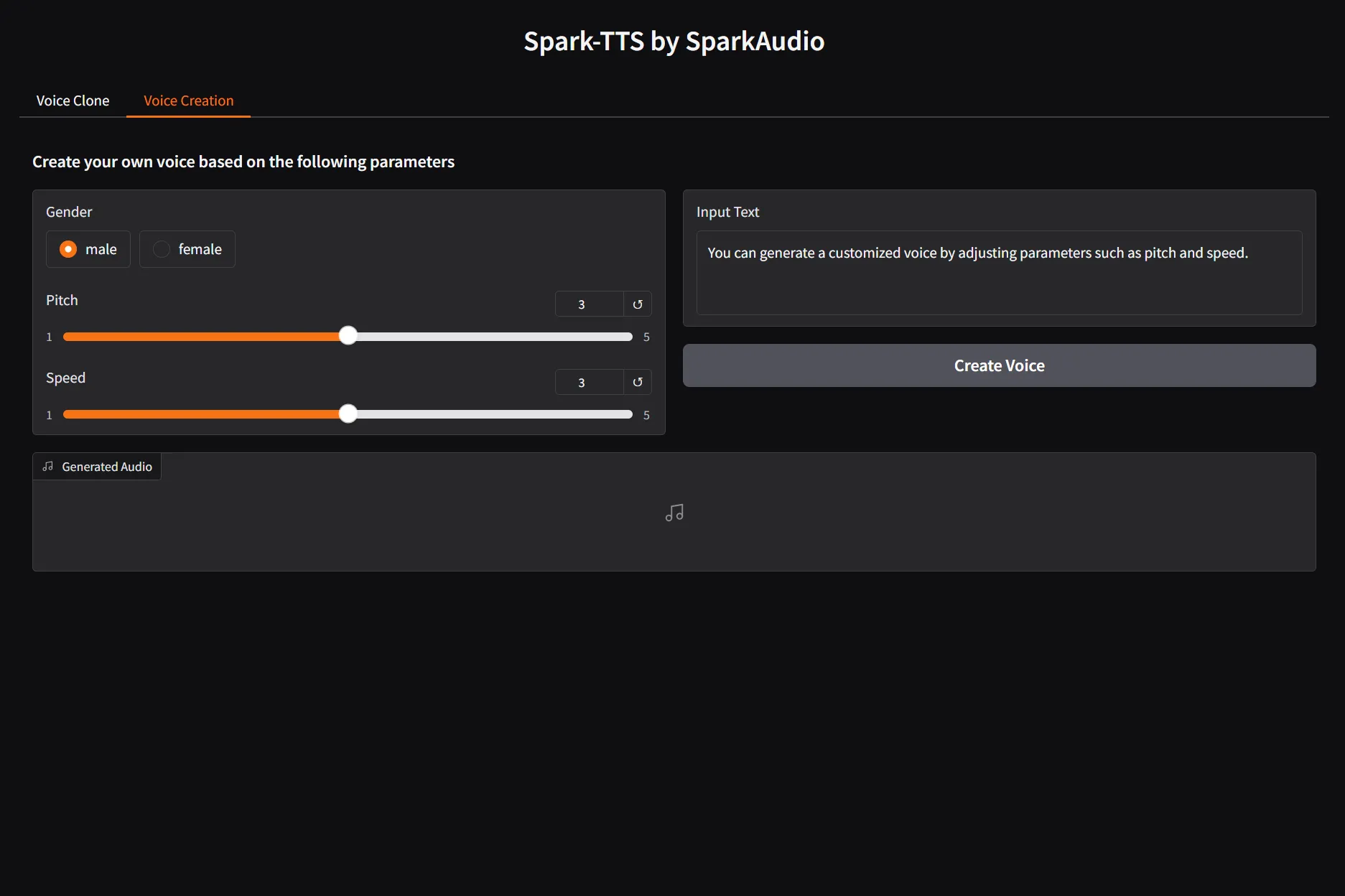
- 上传文件:在界面左侧,点击“Upload PDF(s)”区域,选择你想要转换的一个或多个PDF文件。
- 选择指令模板:在“Instruction Template”下拉菜单中,选择你想要的音频输出类型。例如,选择
Podcast会将内容处理成播客风格,选择Summary则会生成内容的摘要音频。 - 自定义指令(可选):你可以在下方的文本框中修改或完全重写指令,告诉AI你具体想要什么样的内容和风格。
- 生成音频:点击“Generate Audio”按钮。程序会开始处理文件,这个过程可能需要一些时间,具体取决于PDF的大小和复杂程度。
- 试听和下载:处理完成后,生成的音频会出现在界面右侧的“Audio Output”区域,你可以直接在线播放。如果对结果满意,可以下载保存。
- 编辑和迭代:界面右侧还会显示由AI生成的文稿(Transcript)。你可以直接在“Draft Transcript”文本框中编辑文字,然后在“Specific Comments”文本框中输入进一步的修改指令(例如“让语气更活泼一点”),再次点击生成按钮,AI会根据你的新要求重新生成音频。
应用场景
- 辅助学习对于学生和研究人员,可以将冗长的学术论文、教科书或研究报告转换成音频。这样就可以在通勤、锻炼或做家务时收听学习内容,提高时间利用效率。
- 为视障人士提供便利该工具可以将书面材料转换成有声读物,为视力障碍者或阅读困难者提供了一种获取信息的有效方式,让他们能够无障碍地接触各类文档和书籍。
- 内容创作者的工具播客主或视频创作者可以快速将自己撰写的文章、博客或新闻稿转换成音频版本,丰富内容呈现形式,吸引更广泛的听众。
- 语言学习学习外语的人可以利用这个工具将外语文章转换成音频,通过反复收听来练习听力、模仿发音,从而提升语言感知能力。
QA
- 这个工具是免费的吗?PDF2Audio项目本身是开源免费的,你可以自由下载和使用其代码。但是,它依赖于OpenAI的API来处理文本和生成语音,而调用这些API是需要付费的。你需要拥有一个OpenAI账户并为其API使用付费。
- 它支持哪些语言?该工具的核心是大型语言模型(如GPT-4)和文本转语音(TTS)技术。理论上,只要OpenAI的TTS服务支持的语言,这个工具都可以处理。你可以在自定义指令中指定输出的语言。
- 转换复杂的PDF(如图表和公式很多)效果如何?该工具会尝试解析PDF中的文本、图片和表格等元素,并利用语言模型去理解它们的排列顺序和关系。对于图文混排的常规文档,它能生成比较连贯的阅读顺序。但对于包含大量复杂数学公式、化学式或格式非常不规则的PDF,模型在理解和转换时可能会遇到困难,生成的文稿可能需要较多的人工校对和调整。
- 我可以在没有技术背景的情况下使用它吗?对于非技术用户,最简单的方式是使用作者提供的Hugging Face Spaces在线版本,无需任何本地安装。如果想在本地运行,则需要按照“使用帮助”中的步骤进行安装,这需要一些基本的命令行操作知识。一旦安装完成,其网页操作界面就非常直观易用了。